On November 29th, MITRE ATT&CK released the results of their first round of endpoint security evaluations. The evaluations simulated malicious activity from the APT-3 campaign against seven products. While our analysis directly compares the performance of vendors, we want to give ample credit to every vendor with the willingness to participate in this assessment. It appears one vendor may have dropped out during the process, reasons unknown.
The full results for each product can be viewed here: https://attackevals.mitre.org/evaluations.html. The results are displayed on the MITRE ATT&CK killchain table or as a scrollable table broken down by step. However, we didn’t identify an easy way to compare results and contextualize one vendor with respect to other vendors, which is crucial for understanding the relative strengths and weaknesses of the vendors. We were particularly interested in this type of cross-sectional data and the potential benefits it might bring. To perform this cross-sectional analysis, we took the MITRE-provided JSON results, extracted the detection information, and created a simple proof-of-concept database. The database is publicly available on our GitHub along with an example HTML report of detections by technique ID (https://github.com/SecurityRiskAdvisors/mitreevalsdb). If you wish to perform your own queries easily, you can use an in-browser SQLite viewer like http://inloop.github.io/sqlite-viewer/ with the database. In this post we will cover a small subset of the insights this approach to analyzing the MITRE data can produce.
Analysis One: Techniques with the largest detection gaps
The first thing we wanted to understand was where the biggest defensive gaps existed for defensive tooling. To do so, we searched for any technique where a given vendor had no hits in any of the five main detection capabilities then tallied the results. The raw query for this was:
select count(Vendor) as Product_Misses, techniquename, techniqueid from edr where Telemetry = 'no' AND Indicator = 'no' AND Enrichment = 'no' AND General = 'no' AND Specific = 'no' group by techniqueid ORDER BY Product_Misses DESC

From our query, we can see that only 4 (out of 56) techniques were missed by all vendors. It is important to note that 2 of the 4 (“PowerShell” and “Execution through API”) were not directly tested, so no detection capabilities would be expected.
However, we can adjust the above query to exclude weaker detection capability categories such as telemetry. When we filter the results to include just specific and general behaviors, the number of techniques detected by zero vendors dramatically increases.
select count(Vendor) as Product_Misses, techniquename, techniqueid from edr where General = 'no' AND Specific = 'no' group by techniqueid ORDER BY Product_Misses DESC

Whether this is a more accurate depiction of detection is still dependent on the organization. Some organizations pay little-to-no attention to the types of telemetry counted as detection, meaning this query is more accurate. In other cases, more vigilant organizations might pick up that telemetry, meaning the original query was the more accurate one. Additionally, telemetry becomes extremely important during threat hunting activities where a defender needs to track the activities of a malicious actor.
Analysis Two: Detections by Vendor
Another element we wanted to understand was the performance of each vendor. Looking at overall performance (actual detections vs total detection opportunities) of each vendor can help when determining the overall maturity of a vendor. A query for this is:
select vendor, count(vendor) as total_detections from edr WHERE Telemetry = 'yes' OR Indicator = 'yes' OR Enrichment = 'yes' OR General = 'yes' or Specific = 'yes' group by vendor;

We can see that Crowdstrike had the most detections overall with SentintelOne trailing closely behind. However, we can apply the same filtering process as insight one and get a much different picture.
select vendor, count(vendor) as total_detections from edr WHERE General = 'yes' or Specific = 'yes' group by vendor;
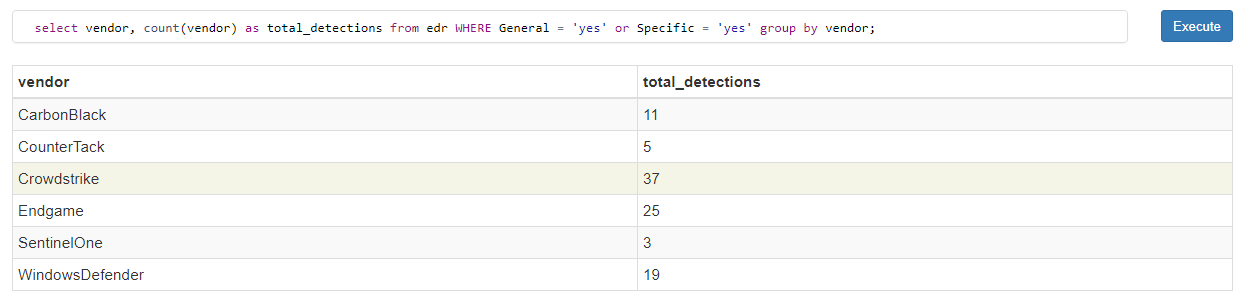
Crowdstrike again remains on top, with a relatively small difference in totals compared to other vendors. However, SentinelOne dropped to last place from second. In this case, the filter of just generic and specific behaviors is meant to help provide insight into which vendor potentially had more robust detections against a wide breadth of techniques.
Analysis Three: Per-technique breakdown
While the previous two queries provide more general insight into the cross-sectional data, what if we need to drill down on a specific technique? For example, if we want to understand how all vendors performed against technique T1110 (Brute Force), we can use a query like
select * from edr where techniqueid == 'T1110'

From this, we get a consolidated view of all performance for all vendors. We can also see any modifiers applied to the detection capabilities in the three rightmost columns (see https://attackevals.mitre.org/methodology/detection-categorization.html). It should be noted that this type of view does lose resolution in comparison to the full evaluation table since it does not break down detection capabilities by step.
If we want to view multiple techniques where there was a detection of a generic or specific behavior for any vendor, we can modify the above query.
select vendor,techniquename,techniqueid,general,specific,tainted,delayed,configuration from edr where techniqueid in ('T1110','T1048') and 'yes' in (general, specific) order by techniqueid

Here we are looking at two techniques (T1048 and T1110) across all vendors for general or specific behavior detections. The rightmost three columns are included since they indicate whether or not the detection has a modifier
Putting to Good Use
While the above information is useful, it should not be considered a direct ranking of product quality. Products should be evaluated in each environment, as part of a defense-in-depth strategy. Consider using these results as a starting point for considering EDR tools, not the decision-maker. To better understand the testing process, MITRE provides a good starting point here: https://attackevals.mitre.org/using-attack-evaluations.html. Ultimately, organizations should be sensitive to the differences in detections across vendors and perform thorough research before choosing the best one for their environment.
Links
- Database used: https://github.com/SecurityRiskAdvisors/mitreevalsdb
- MITRE ATT&CK Evaluations Site: https://attackevals.mitre.org/
- Additional analysis: https://go.forrester.com/blogs/measuring-vendor-efficacy-using-the-mitre-attck-evaluation/
- The data graphed: https://twitter.com/DAlperovitch/status/1070443452754731008

Evan Perotti
Evan specializes in network penetration testing, web application security testing, open source intelligence gathering, and security testing process automation.
He has experience in a variety of industries including retail, insurance, financial services, and healthcare.

Mike Pinch
Mike is Security Risk Advisors’ Chief Technology Officer, heading innovation, software development, AI research & development and architecture for SRA’s platforms. Mike is a thought leader in security data lake-centric capabilities design. He develops in Azure and AWS, and in emerging use cases and tools surrounding LLMs. Mike is certified across cloud platforms and is a Microsoft MVP in AI Security.
Prior to joining Security Risk Advisors in 2018, Mike served as the CISO at the University of Rochester Medical Center. Mike is nationally recognized as a leader in the field of cybersecurity, has spoken at conferences including HITRUST, H-ISAC, RSS, and has contributed to national standards for health care cybersecurity frameworks.