Intro
While I spend most of my time performing offensive security assessments (pentesting, red teams, web apps, etc), I have a side interest in DevOps, especially infrastructure and automation. Recently, I had some free time so I decided to check out Amazon’s continuous integration/deployment (CI/CD) tooling and apply it to offensive operations in the form of a payload server build pipeline. A payload server build pipeline is a particularly interesting idea to me for a number of reasons. Primarily, it allows team members to both codify their techniques into a single source of truth, as opposed to disparate sources like operator VMs, and to streamline the process of going from payload source creation to payload delivery to a target. In this post, I will specifically be covering using AWS CodePipeline to automate the deployment of genesis script (gscript) payloads to a payload server.
Pipeline Components
AWS CodeCommit: Source control repository
AWS CodePipeline: Main pipeline for automation
AWS CodeBuild: Builds payloads from source control
AWS Lambda: Functions as a service
AWS S3: Object storage
AWS EC2: VPS
AWS SSM: System management
Pipeline Flow
- Commit .gs (gscript) file(s) to payload repository
- CodePipeline starts
- CodeBuild compiles .gs file(s) to executables
- Executables stored in S3
- Lambda uses SSM’s run command to have EC2 instance download files
- Files moved to web directory
Setup – Prerequisites
Since the above flow uses SSM, the EC2 instance must have the SSM Agent installed. If the instance was launched using a standard Amazon Linux, Windows Server, or Ubuntu 16.04/18.04 AMI, this is already installed. However, the instance must also have an instance role that allows the SSM Agent to register. As this instance also needs access to download from S3, we can use the AmazonEC2RoleforSSM managed policy to create an instance role then attach it to the instance.

EC2 instance role for SSM

Role attached to instance
The only other component needed is a CodeCommit repository with a build configuration YAML file (buildspec.yml).

CodeCommit repository
The directory structure can be whatever you choose as long as the buildspec.yml is in the root. For this project, I am using the gs directory to store the gscript payloads and the bin directory to stored the compiled executables.
Creating the Pipeline
Once the above prerequisites are met, we can create the pipeline. In the CodePipeline console, create a new pipeline that uses CodeCommit as a source and that points towards the payload CodeCommit repository. Keep in mind that the pipeline will trigger on each commit to the selected branch. To avoid triggering a build on every small change, consider using a staging branch for minor changes then merging them to the master cumulatively.

Creating the pipeline
When setting the build configuration, we can leverage the existing gscript Docker image to perform the compilation.
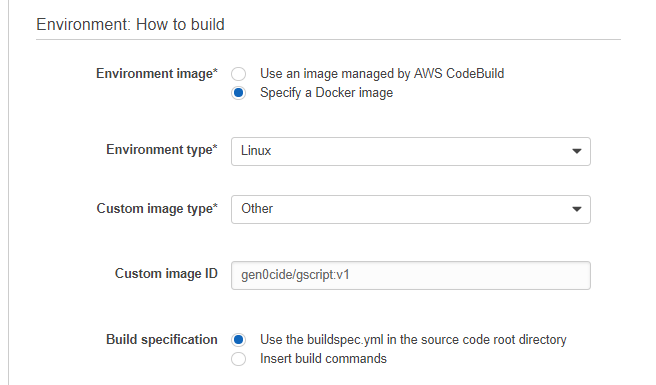
Build settings
In the advanced settings, I added an environment variable called GS_ARCH, which will be used to tell gscript which architecture to build for; in this case amd64.

Environment settings
Once the pipeline is created, it should resemble the following:

New pipeline
Building the Spec
Now that the pipeline is in place, we need to complete the buildspec.yml so that the gscript payloads are compiled properly. Below is an example buildspec.yml that I used for this project:
- Line 1: version for CodeBuild (this cannot be an arbitrary value – see buildspec reference guide linked above)
- Line 3-6: These are the phases for the build and their accompanying commands. In this case, there is only one phase (build). The command to be run will use gscript to compile each payload individually. The environment variable from the pipeline creation steps is used here as well. Alternatively, you can take a more involved approach and have gscript compile payloads using multiple input files.
- Lines 7-9: This indicates which items from the build process should be uploaded to S3. In this case, only the bin directory (compiled files) will be uploaded.
Now, when a new gscript file is committed to the repository, the build will run, take each gscript file in the gs directory, compile them, and save them to the bin directory, which gets shipped to S3.
Serving the Files
The final stage of the pipeline is to ensure the compiled files make it to the payload server. To do this, we can make a Lambda function that triggers when the CodeBuild process completes and pass the build artifact location to that Lambda. This Lambda will need to have permissions to send SSM commands to instances as well as put pipeline statuses to CodePipeline. Without pipeline permissions, the stage will appear to hang on being in-progress until it times out. Here is the policy I used for this project:
and the associated Lambda code, written in Python 2.7:
- This function uses two environment variables:
- INSTANCE_ID: the EC2 instance to run the command on
- PAYLOAD_DIR: the payload directory where the executables should be placed
- The target EC2 instance should have unzip and awscli installed
- While the awscli is used to copy the files from S3, you can alternatively generate a pre-signed S3 URL for the artifact then have the EC2 instance download that without the awscli. Keep in mind that you will have to adjust the Lambda permissions to allow it to generate signed URLs.
- The EC2 instance’s web server should be configured to serve the payload directory.
Once the Lambda is created, we can add the final stage to the pipeline.

Adding a Lambda stage
Putting It All Together
To test the pipeline, commit a valid gscript payload to the gs directory of the CodeCommit repository. You can find example scripts here. The pipeline should trigger on the commit, build the executables, store them in S3, then serve them on the EC2 instance. If all goes well, the pipeline status should be green.

Successful pipeline completion
Additionally, you should see a successful SSM command in the SSM console

Successful SSM command
and the files in the payload directory

Payload server
Closing Thoughts
Hopefully this has provided you with an idea of how AWS CI/CD tooling can be used for offensive operations. While some of the methods in this post may not be particularly scalable, they can be used as a baseline when starting to create a payload server pipeline of your own.

Evan Perotti
Evan specializes in network penetration testing, web application security testing, open source intelligence gathering, and security testing process automation.
He has experience in a variety of industries including retail, insurance, financial services, and healthcare.